

Datakwaliteit vormt de ruggengraat van effectieve besluitvorming binnen organisaties. Betrouwbare en nauwkeurige gegevens zijn essentieel omdat ze de basis vormen waarop cruciale beslissingen worden genomen. Slechte datakwaliteit kan leiden tot foutieve interpretaties en misleidende conclusies, wat de basis vormt voor beslissingen die mogelijk afwijken van de optimale koers voor organisaties. En... het verbeteren van je datakwaliteit is nodig om goed gebruik te kunnen maken van AI. Dus werk aan de winkel, zeker nu Copilot sinds vorige week is gelanceerd voor iedereen met een Microsoft 365 account.
Daarnaast leidt het verbeteren van datakwaliteit tot kostenbesparingen, verhoogde efficiëntie en versterkt het vertrouwen en de geloofwaardigheid van beslissingen. Het is een sleutelfactor voor een concurrentievoordeel, aangezien organisaties met hoogwaardige gegevens beter in staat zijn om te innoveren, kansen te identificeren en te groeien in een snel veranderende omgeving.
Kortom, de kwaliteit van data is niet alleen essentieel maar ook onmisbaar voor het succes van elke organisatie.

In de moderne wereld speelt data een essentiële rol in besluitvorming binnen organisaties. Het proces van data-opschonen en -structurering is cruciaal om ruwe gegevens te transformeren naar bruikbare inzichten. Onderstaande stappenplan begeleidt organisaties door identificatie, opruiming, verrijking, gegevensbeheer, gebruik van nieuwe technologieën en continue monitoring om de kwaliteit van data te verbeteren. Deze stappen bieden een stevige basis voor effectieve beslissingen op basis van betrouwbare informatie.
Een essentiële eerste stap is het begrijpen van de data die een organisatie bezit. Dit omvat het identificeren van alle datasets en het vaststellen van de oorsprong, structuur en relevantie van deze gegevens. Denk hierbij aan data die is opgeslagen in verschillende databases, Excel sheets, file-servers of SharePoint. Door een grondige analyse van de data te maken, kunnen potentiële problemen zoals inconsistenties, ontbrekende waarden of duplicaten aan het licht komen.
Met inzicht in de data is de volgende stap het opschonen van de gegevens. Dit omvat het elimineren van dubbele records, het corrigeren van foutieve waarden en het standaardiseren van formaten. Bij één van onze klanten kwam ik bijvoorbeeld ruim 3000 eenheden van artikelen tegen, waarvan maar liefst 1000 nog relevant waren. Het gebruik van data-analysetools of zelfs simpelweg Excel kan helpen om processen te versnellen en de consistentie in de gegevens te waarborgen.
Na het opruimen van de data is het waardevol om deze te verrijken. Dit houdt in dat ontbrekende gegevens wordt aangevuld of dat aanvullende context wordt toegevoegd aan bestaande gegevens. Dit kan worden bereikt door externe bronnen te integreren of door gegevens te verbinden met andere interne datasets. Denk hierbij aan het integreren van data van partners of leveranciers of het simpelweg samenvoegen van klantgegevens uit verschillende interne bronnen, zoals verkoop-, service-, en marketinggegevens.
Het proces van gegevensbeheer en het opstellen van standaarden is van cruciaal belang voor het handhaven van datakwaliteit op de lange termijn. Dit omvat het definiëren van processen voor gegevensinvoer en -validatie, het regelmatig controleren van de datakwaliteit en het trainen van gebruikers om deze standaarden te handhaven.
Het integreren van geavanceerde technologieën zoals kunstmatige intelligentie (KI) kan helpen bij het automatiseren van processen voor het verbeteren van datakwaliteit. KI kan helpen bij het identificeren van patronen, het voorspellen van ontbrekende waarden en het verbeteren van de algehele nauwkeurigheid van de gegevens.
Datakwaliteit is geen eenmalig proces, maar een continu proces. Het is essentieel om regelmatig de kwaliteit van gegevens te monitoren en waar nodig verbeteringen aan te brengen. Dit omvat het verzamelen van feedback, het evalueren van de effectiviteit van toegepaste maatregelen en het aanpassen van strategieën om voortdurende verbetering te waarborgen.
Door deze stappen te volgen, kunnen organisaties de kwaliteit van hun data verbeteren, waardoor ze beter gepositioneerd zijn om betrouwbare analyses te maken en gefundeerde beslissingen te nemen voor hun bedrijfsvoering.
Copilot, een geavanceerde AI-tool van Microsoft, fungeert als jouw virtuele assistent, waardoor je moeiteloos door Office 365 kunt navigeren, inclusief Word, Excel en PowerPoint. Zo kun je in Word met Copilot bijvoorbeeld vragen om een offerte te genereren op basis van productinformatie, prijslijsten en voorwaarden die zijn opgeslagen in SharePoint. Of in Excel vragen om een analyse van de cijfers in het desbetreffende Excel bestand.
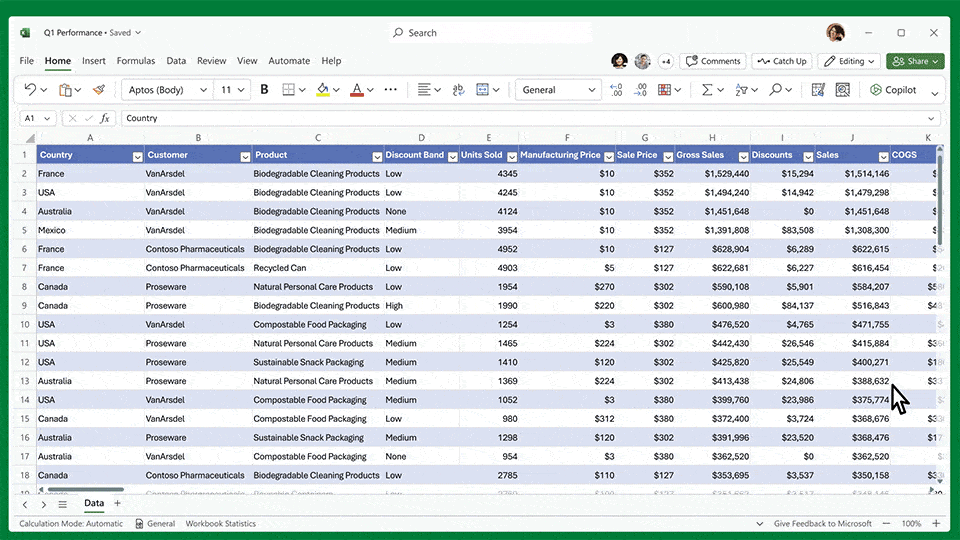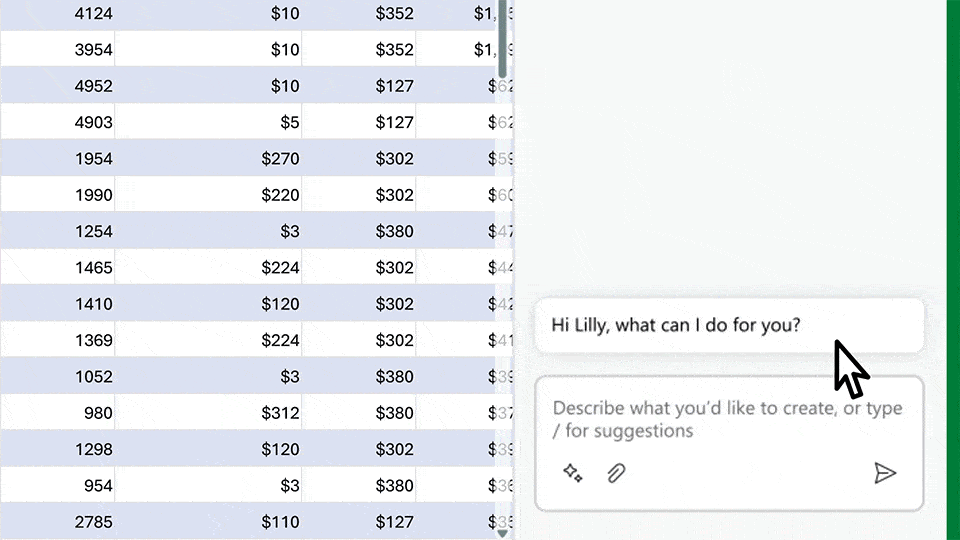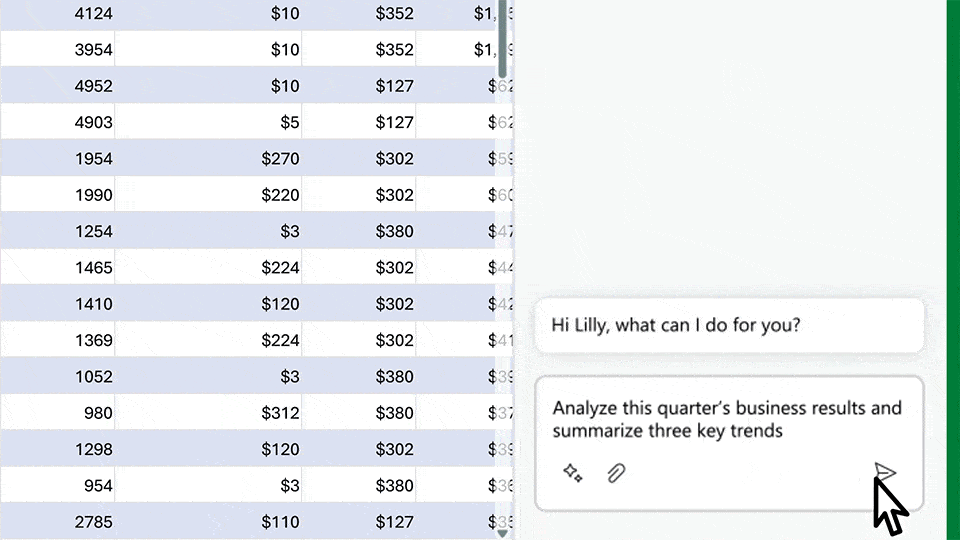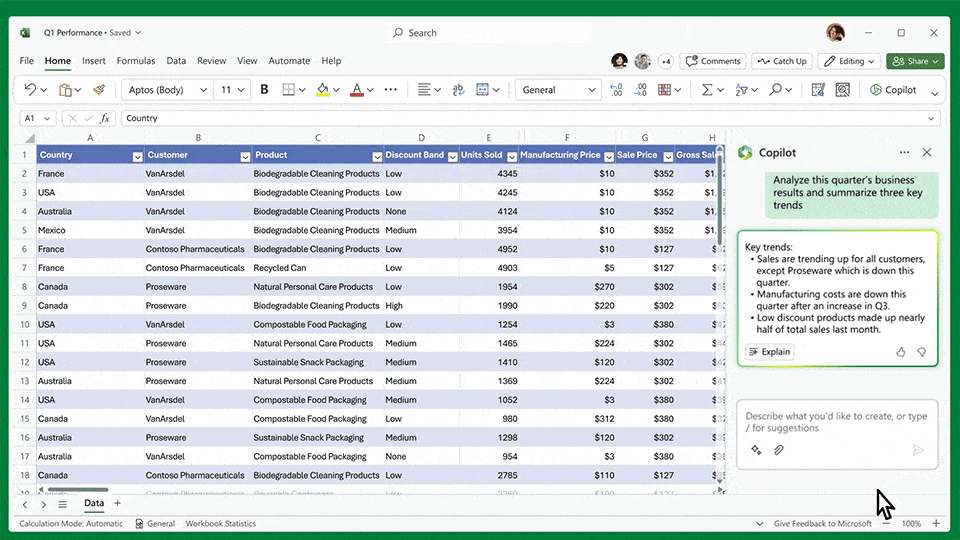
Het belang van het beschikbaar maken van de juiste data wordt hiermee benadrukt, aangezien dit essentieel is voor het optimaal benutten van AI-tools zoals Microsoft Copilot. Het samenspel tussen Copilot en hoogwaardige data in onder andere SharePoint versterkt niet alleen de gebruikerservaring, maar verbetert ook de besluitvorming. Door je datakwaliteit te verbeteren, maak je je bedrijf klaar voor een geavanceerde en efficiënte manier van werken met AI/Copilot.
Nu we weten hoe belangrijk het is om de kwaliteit van je data te verbeteren (stap 1), gaan we nu kijken waarom het belangrijk is om je data op te schonen (stap 2).
Bij het gebruik van data zijn de meeste mensen het erover eens dat je inzichten en analyses zo goed of slecht zijn als de data die je gebruikt. Slechte data leidt tot slechte analyses. Het opruimen van data is een van de belangrijkste stappen voor jouw organisatie voor het nemen van beslissingen op basis van kwalitatieve data. En dat is eens te meer nodig met de komst van AI. Pas als je data opgeruimd is en van goede kwaliteit, kun je goed gebruikmaken van AI.
Met het opschonen van data bedoelen we het proces van het identificeren en corrigeren van onnauwkeurigheden, fouten, dubbele waarden en inconsistentie in data. Het doel ervan is om de kwaliteit van de data te verbeteren door het minimaliseren van onjuiste, onvolledige of irrelevante informatie, waardoor de betrouwbaarheid en bruikbaarheid ervan toenemen.
Data kan soms gewoon fout zijn, vooral wanneer het handmatig wordt ingevoerd door mensen. Neem bijvoorbeeld de CRM-gegevens. De gegevens worden gegenereerd door verkoopmedewerkers die bijvoorbeeld een datumveld of hoeveelheden zoals omzet verkeerd invullen of per ongeluk duplicaten maken.
De gebruikers gebruiken verschillende benamingen voor het zelfde gegeven. Bijvoorbeeld, waar een persoon als eenheid voor een artikel “Liter” invoert, voert een andere gebruiker “L” of “Ltr” voor zelfde maateenheid. Data is goed, alleen dezelfde data heeft een andere benaming, waardoor inconsistentie en vervuiling ontstaat.
Denk hierbij aan logbestanden die automatisch gegenereerd worden door systemen. Hierbij gaat het om een dataformaat dat handig is voor een ander systeem, maar niet voor de gebruiker.
Zelfs als de gegevens zelf schoon zijn, kunnen ze verspreid zijn over verschillende bronnen. Om ze bruikbaar te maken, moet je data op de een of andere manier centraliseren, zodat data kunnen worden gecombineerd. Denk hierbij aan Microsoft Azure Blob Storage om gegevens op één locatie op te slaan en gemakkelijk toegankelijk te maken.

Het opruimen van data is belangrijk omdat het de nauwkeurigheid van analyses en besluitvorming beïnvloedt. Immers, onjuiste data kan leiden tot verkeerde conclusies en beslissingen. Door de data op de juiste manier op te ruimen, kunnen organisaties de betrouwbaarheid van gegevens vergroten, wat essentieel is voor een juiste en effectieve besluitvorming.
Hier zijn enkele fundamentele stappen die je kunt volgen bij het opruimen van data:
1. Identificeren van dubbele of irrelevante gegevens:
Gebruik datakwaliteitstools om duplicaten te identificeren en te verwijderen. Dubbele records kunnen de analyse vertroebelen en de resultaten beïnvloeden.
2. Corrigeren van foutieve waarden:
Identificeer en corrigeer onjuiste, inconsistente of ongeldige waarden in de data. Dit kan onder meer het opsporen en aanpassen van spelfouten, onrealistische numerieke waarden, of andere afwijkingen omvatten.
3. Standaardiseren van formaten:
Zorg ervoor dat gegevens consistent worden opgeslagen in gestandaardiseerde formaten. Bijvoorbeeld, standaardiseer datums, adressen, telefoonnummers, valuta’s, en andere gegevensvelden om uniformiteit te garanderen.
4. Validatie van gegevenstypen:
Controleer of gegevenstypen overeenkomen met de verwachte typen voor elk veld. Bijvoorbeeld, controleer of datumvelden als datums worden opgeslagen en niet als tekst.
5. Hanteren van ontbrekende waarden:
Bepaal een strategie om om te gaan met ontbrekende waarden, zoals het invullen van ontbrekende gegevens op basis van gemiddelden of andere statistieken, of het markeren van records met ontbrekende informatie.
6. Normalisatie van data:
Breng data naar een normaal vormniveau om redundantie te verminderen. Bijvoorbeeld, als gegevens op meerdere plaatsen worden opgeslagen, creëer dan een aparte tabel om duplicatie te voorkomen.
7. Gegevensconsistentie:
Controleer de consistentie van gegevens over verschillende tabellen of datasets. Zorg ervoor dat dezelfde entiteit (zoals een klant of product) consistent wordt weergegeven.
8. Gebruik van patroonherkenning:
Maak gebruik van geavanceerde technieken zoals patroonherkenning om afwijkende patronen te identificeren en aan te pakken.
9. Automatisering van het opruimproces:
Gebruik automatiseringstools en scripts om het opruimproces te versnellen en menselijke fouten te minimaliseren.
10. Documentatie:
Documenteer alle stappen van het opruimproces om een transparant en reproduceerbaar proces te waarborgen.
Het is belangrijk om het opruimen van data als een doorlopend proces te beschouwen, vooral als nieuwe gegevens worden toegevoegd. Regelmatige data-audits en onderhoud zijn van essentieel belang om de kwaliteit van de gegevens in de loop van de tijd te behouden.
Datakwaliteit is cruciaal voor effectieve besluitvorming. Het proces van data-opruiming en het structureren van data biedt een raamwerk om gegevens te verbeteren voor betrouwbare analyses. Identificeren, opruimen, verrijken en beheren van data zijn essentieel voor betere datakwaliteit.
Verbetering van datakwaliteit kan worden bereikt door regelmatige audits, gegevensstandaardisatie, gebruik van geavanceerde tools en het onderzoeken van externe bronnen. Door deze stappen te volgen, kunnen organisaties waardevolle inzichten verkrijgen uit hoogwaardige data voor betere besluitvorming.
Daarnaast legt det opruimen van je data de basis voor betrouwbare analyses en weloverwogen beslissingen. Begin vandaag nog met het implementeren van de bovenstaande stappen en ontdek de transformatie die het kan brengen naar de kwaliteit van je gegevens.
Ons team van experts staat klaar om je te begeleiden bij dit proces en ervoor te zorgen dat je data het krachtige instrument wordt dat het zou moeten zijn. Neem hieronder contact met ons op voor advies, of om te bespreken hoe we je kunnen ondersteunen bij het optimaliseren van je data.







Meldingen